At the end of the summer of 2014 I undertook a 2-week internship with the Letters of 1916 project. Having chatted with Susan Schreibman, the project’s principle investigator, we decided that I should do a feasibility study that would consider how best to integrate the letters data into the Semantic Web. In this blog post, I will give an account of that study and will briefly introduce the Semantic Web from a technical point of view.
Linked Open Data and the promise of greater data mobility
In 2006 Tim Berners-Lee, the man credited with the invention of the World Wide Web, outlined a list of criteria with which to judge how open and linkable a dataset is (Berners-Lee, 2006). Whereas, the WWW had been envisaged as a network of human-readable documents (text, images and video mainly) that were linked via hyperlinks, Berners-Lee’s new list targeted data. Unsurprisingly perhaps, Berners-Lee’s web of data was to use the same infrastructural model as had worked so well with the document web. Data would exist as addressable resources that could be fetched using the same HTTP protocol that we use to retrieve web pages and images. It was the simplicity of Berners-Lee’s new data model that made it so appealing at the time and it is still this bare bones quality that is Linked Open Data’s strongest asset.

In order for a dataset to get one star, it has to be made accessible online and access requests should be covered by an open license such as is set out by the various Creative Commons licenses (http://creativecommons.org/). For two stars, the data must be structured. An example of unstructured data is a raster image resource that normally can only be interpreted by a human. Linked Open Data is concerned with data that can be read by machines and this is an important point that we will return to.
For the next star, the data within the dataset needs to be structured using a format that is non-proprietary. Digital data frameworks have traditionally been created using open source development models or by a closed group that chooses to keep the inner structure of the framework hidden from the wider public for whatever reason. Berners-Lee is an advocate of making the structure of all data open. An example of an open data framework is CSV or Comma Separated Values and he contrasts this against the closed standard of an Excel file.
Four stars are awarded to data, which is addressable using Uniform Resource Identifiers. URIs are a superset of URLs, which we are all familiar with as the identifiers of web pages and other document web resources. The difference between URIs and URLs is that URIs might look like URLs but they need not necessarily point to a web resource. They may simply be a data identifier in the same way that a library catalogue might use the number 100 to label a particular book that forms a part of its collection.
URIs are, however, typically dereferenceable (they point to Internet resources) and it is this aspect of Linked Open Data nodes that makes them so powerful as components of distributed information systems. Whereas, in non-LOD contexts, data can only reference other data that is contained within the same dataset, LOD data can link to data that contained outside of the source and it is this inter-dataset linkage that gives the web of data its name.
The final star is granted to datasets that practice exactly this type of external linking. An example of this might be to state that a data node is associated with a particular geographical location and instead of creating a digital representation of this location in the source dataset, you would link to a external resource in an open dataset such as LinkedGeoData.org (http://linkedgeodata.org).
RDF and the Semantic Web
Linked Open Data, as you will no doubt have noticed, is a fairly generic information model. In no place in Tim Berners-Lee’s description (http://5stardata.info/) of it, does it state that it needs to be implemented in one specific way or another. As such, it should be viewed as an information philosophy and all philosophies need an implementation to be realised. By far the most popular way of practicing the LOD way is to use Resource Description Framework (http://www.w3.org/RDF/) or RDF.
RDF is built upon the very simple foundational unit of the triple and it was designed to seamlessly integrate into a URI-based information network such as is described for Linked Open Data. Triples are made up of a subject, a predicate (or relationship) and an object and the basic idea is that any complex meaning can be broken down into a series of interrelated triples.
An example of a triple is ‘the boy’s name is Tom’. Here, the boy is the subject, ‘whose name is’ is the predicate and ‘Tom’ is the object. ‘Tom is short for Thomas’. This second triple contains takes the previous object as its subject. The predicate is now ‘short for’ and the object is the string ‘Thomas’. You can see that triples, while relatively simple in structure, can be combined to encode great complexity.
In practice, triples tend to contain URIs for each of their three elements and it makes sense to think about a network of triples as a graph of data, in which subjects and objects are represented as nodes with the lines that connect them representing the linking predicate. The example above could be represented in a graph as follows.
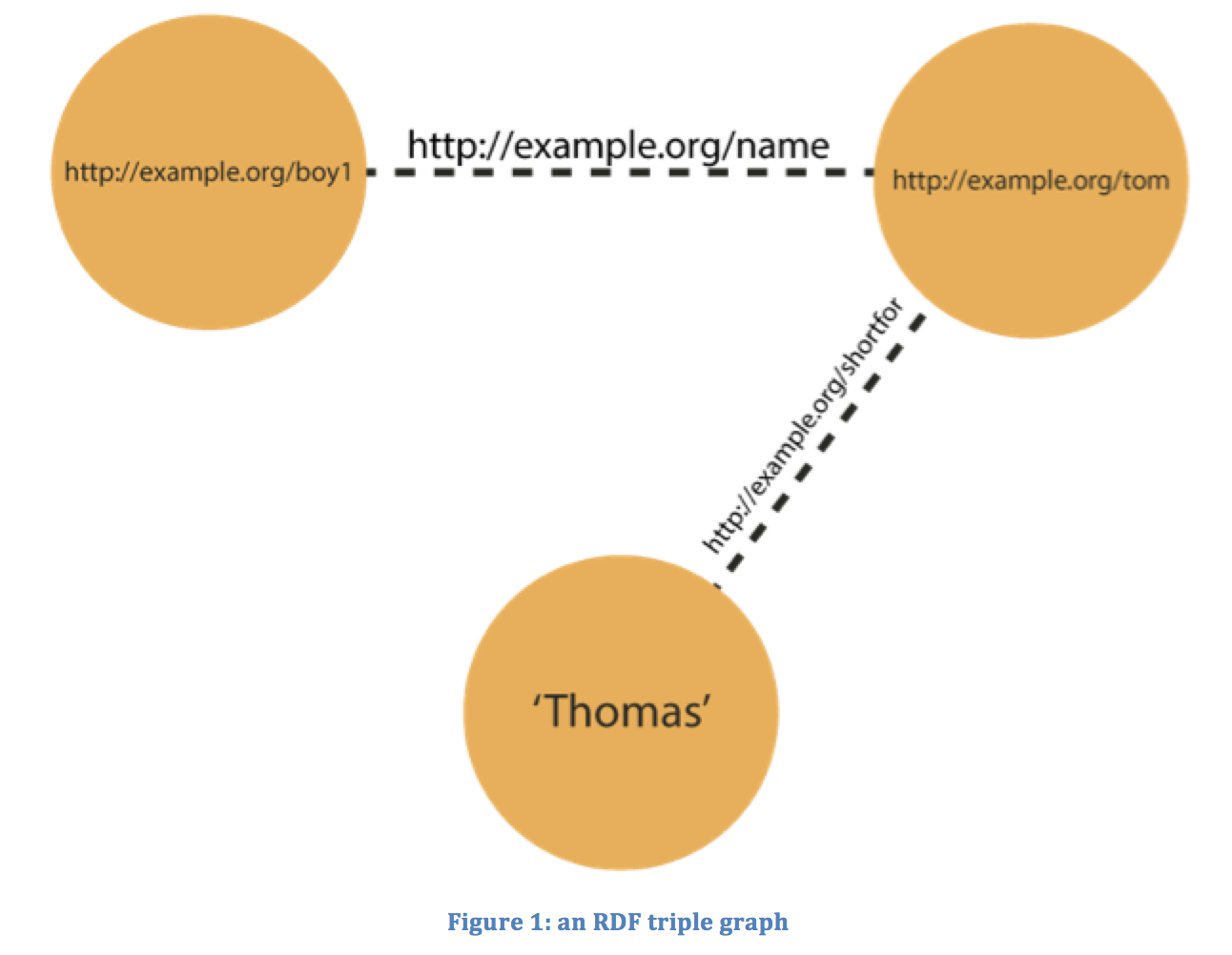
The encoding of meaning is one of the most rewarding and often most difficult objectives of the knowledge sharing process. We have already shown how a number of concepts related to the boy named Tom might be encoded but there is no reason why these might not be represented in an alternative fashion and perhaps this second representation might even be deemed ‘better’ than the first.
The subject of Linked Open Data meaning is all about semantics and the meaningful web of data has come to be referred to as the Semantic Web, and the way in which we decide to model meaning about any set of data is called its ontology. The problem highlighted above in which any one set of ‘objective’ concepts might come to be represented in two or more ways is one of the key challenges when publishing data to the Semantic Web. In theory you want to provide a web of data that is free to be expressed in any way that the data provider decides best but in practice a dataset is immeasurably more valuable if it is structured using an ontology that is already used by other datasets.
These public datasets might already be familiar, as they have come to be used to successfully model a lot of the data occupying the Semantic Web today. Friend of a Friend (http://www.foaf-project.org/) or FOAF is used to model relationships that exist between people and things. The Dublin Core Schema (http://dublincore.org/) is used extensively to structure data that represents digital and physical objects. And there are many other ontologies besides.
This section has been necessarily brief. If you want to find out more about RDF and ontologies please visit my web site, linkedarc.net (http://linkedarc.net). For now though, we will continue to investigate how these techniques might be applied to the problem of sharing the Letters of 1916 dataset.
Structuring letters data
I received a CSV file containing a representation of all of the data collated thus far by the Letters of 1916 project. It contained a number of fields that I half expected, such as a title, description, author, recipient and related addresses and some other fields whose value for me at least was less obvious, such as an ‘encode’ field and a copyright field. It also contained a field for the transcription of the text of the letter and while this is obviously a set of data that is of particular interest to the project as a whole, as will become clear, it was of less value for my own project.
I set about tidying up the data in a process that is known as data cleaning. This basically means that you take the data into a data cleaning application (I used Google Refine), you normalise it or make all of the contents of the fields adhere to a particular data requirement (e.g. you standardise all the dates contained in the DATE_created field), and finally you output your cleaned up data. In my case, I wanted to output RDF data and thankfully the people at DERI (https://www.deri.ie/) at NUI Galway have written a Google Refine plugin to allow just that.
We talked earlier about ontologies and how it is best to use a public and well-regarded ontology to structure your data as this will make it more valuable as a data resource. I decided to use the Schema.org (http://schema.org/) ontology for the letters for this reason. This ontology has been developed by the major search engines in an attempt to allow web content providers structure their data in a more standardised way. It was designed to model creative objects, such as web pages, blogs, images and videos. It is also well documented, which is a great help and not a guaranteed feature of many ontologies, particularly for domains that deal with cultural heritage material.
The Schema.org ontology does not, however, contain a class to model letter data and so I needed to extend the model to allow for this. Schema.org classes are hierarchical and the CreativeWork (http://schema.org/CreativeWork) class contains the majority of the fields that I needed to model the letters data.
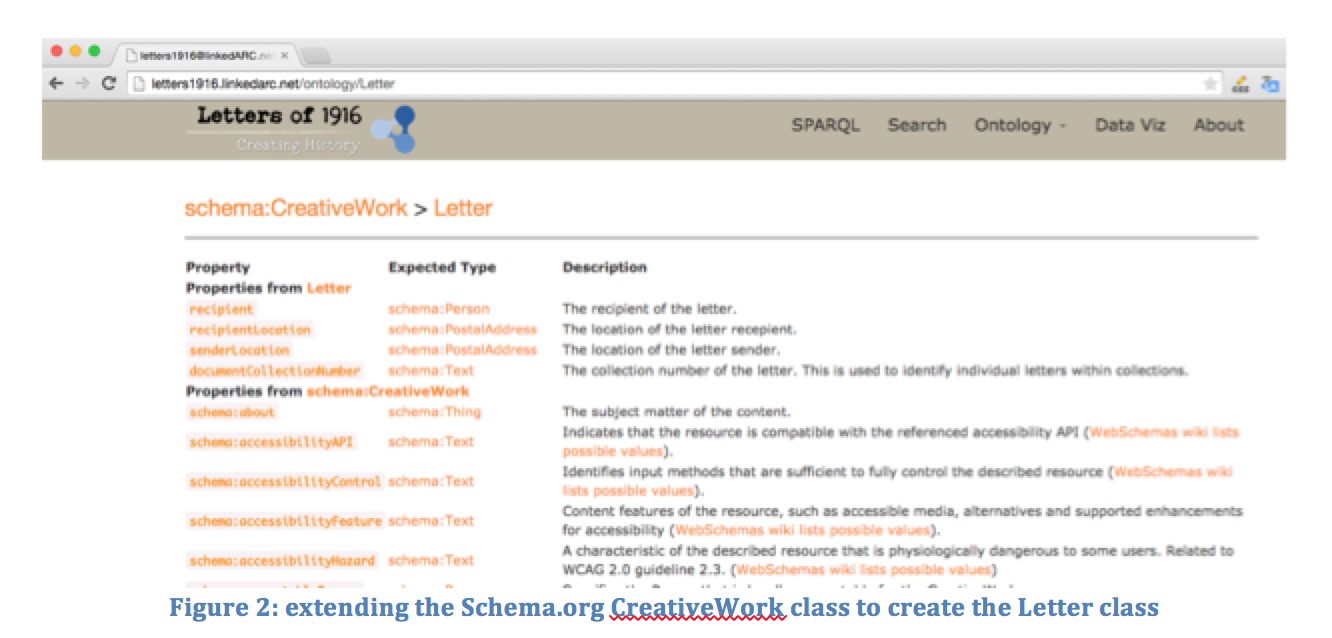
Figure 2 shows a webpage that I created to document the new Letter class. Extending ontological classes is a powerful feature of Semantic Web programming. It allows you to gain the benefits of using a well-known public ontology, while also enjoying the freedom that customisation provides.
Publishing the letters data to the Semantic Web
With the RDF Google Refine output in hand, I needed a datastore that is capable of hosting RDF triple data. These types of databases are known in the business as triplestores and the Apache Jena (https://jena.apache.org/) offering is a popular choice. It is simple to setup and I run mine (which hosts the Letters of 1916 data as well as other RDF datasets) off of an Amazon EC2 (http://aws.amazon.com/ec2/) instance running Linux Ubuntu (http://www.ubuntu.com/) v12.04.
RDF can be served to users in a number of different ways. You might decide to simply make it available as RDF file dumps. This is an easy approach but not particularly useful for data discovery. You could write a Web API to allow access into the triplestore and while this is a common approach to data interfacing these days, it falls down as Web APIs are proprietary and thus the client will need to write custom code to access it.
Or you could decide to use SPARQL as the gateway into your data and I have come to view this last approach as by far the most flexible way of making your Linked Open Data available. SPARQL is a querying language that allows you to ask detailed and specific questions of your dataset. Thankfully, Apache Jena comes with the Fuseki SPARQL interface and so adding SPARQL functionality to a Jena triplestore is relatively straightforward (Figure 3).
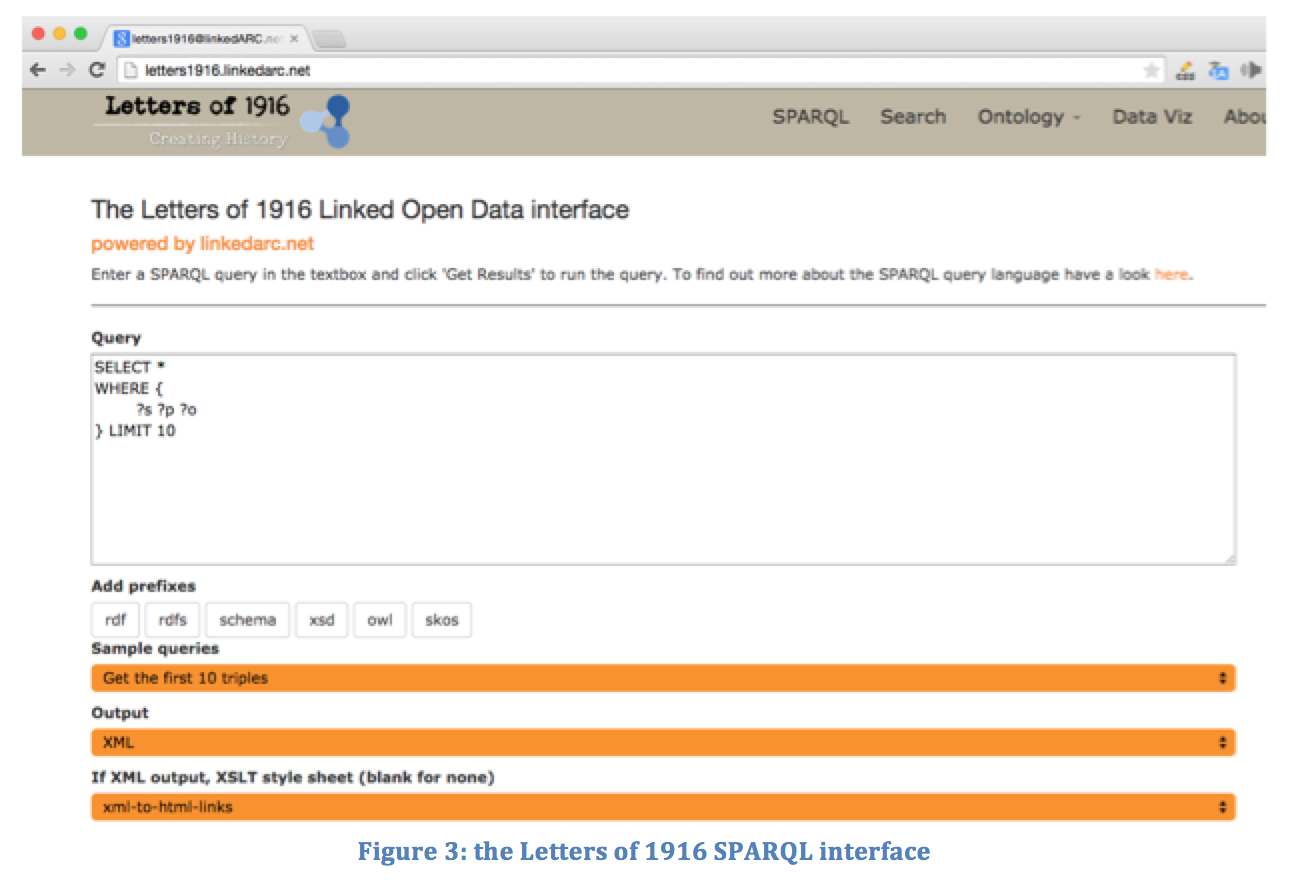
For information about how to construct SPARQL queries, please see a guide (http://linkedarc.net/about/sparql.php) that I have written for creating SPARQL queries of archaeological datasets. Here is an example SPARQL query that asks the Letters triplestore for all of the letters that were sent to an address in Leitrim.

And here is the response in a human-readable HTML format.
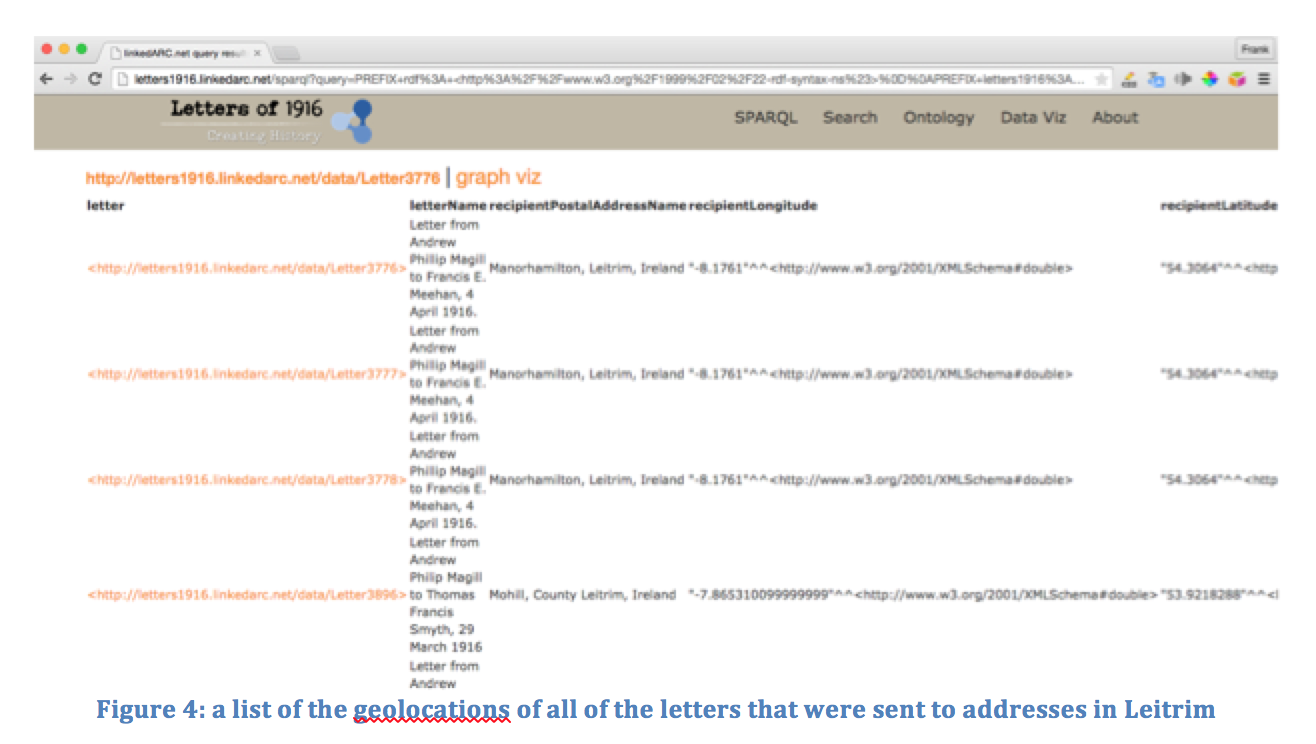
Note how the SPARQL query has returned the longitudinal and latitudinal values for each of the Leitrim addresses. This additional data was added to the dataset by making calls to the Google Maps Reverse Geocoding Web API (https://developers.google.com/maps/documentation/javascript/examples/geocoding-reverse) during the data cleaning stage in Google Refine.
RDF data such as this tends to be designed for the consumption of machines and often people complain that their queries to the Semantic Web return data that is too esoteric to be comprehensible. An example employment of this data might be to construct an interactive map interface that would query the Letters datastore and display the results of that query to the user in real-time. This is where the true power of Linked Open Data practices are realised in the creation of dynamic data-driven applications that actively go out and query in real-time online data resources, synthesise and display the results to the user in a meaningful and narrative-based manner. This approach encourages re-use of data resources, which ultimately leads to new interpretation and new knowledge.
The Letters of 1916 is a wonderful example of a crowd-sourced community-based project that engages its user base with the social histories that are so often neglected by the grand narratives. Data collection is, however, only one aspect of the data process and projects such as this need to be constantly considering how best to use their collected data going forward. Linked Open Data and Semantic Web techniques open up a wide spectrum of possibilities for the use and linking up of different cultural heritage datasets. They provide a re-use model that will allow the Letters of 1916 content to provide inspiration for new projects for many years to come.
Note that the project website (http://letters1916.linkedarc.net/) that accompanies this research is currently not accessible to the public. Please check back for updates.
 Frank Lynam has more than a decade of experience working in R&D in the technology sector. He completed his BA at Trinity College Dublin where he read Ancient History and Archaeology and Italian. He studied Mesopotamian archaeology and the archaeology of South Asia for his MPhil in Archaeology at the University of Cambridge. He is currently in the final year of his PhD at Trinity College Dublin where he is a part of the Digital Arts and Humanities PhD programme. His thesis considers the synthesis of the archaeological method with Linked Data, Semantic Web and Big Data techniques.
Frank Lynam has more than a decade of experience working in R&D in the technology sector. He completed his BA at Trinity College Dublin where he read Ancient History and Archaeology and Italian. He studied Mesopotamian archaeology and the archaeology of South Asia for his MPhil in Archaeology at the University of Cambridge. He is currently in the final year of his PhD at Trinity College Dublin where he is a part of the Digital Arts and Humanities PhD programme. His thesis considers the synthesis of the archaeological method with Linked Data, Semantic Web and Big Data techniques.