In Autumn 2015, the annual Text Encoding Initiative (TEI) conference was held in Lyon, France. The Text Encoding Initiative (http://www.tei-c.org/index.xml), is a non-profit consortium composed of academic institutions, individual scholars and research project teams from around the world engaged in the maintenance and support of the standard for the encoding electronic texts in the humanities. This blog post will examine how The Letters of 1916 uses TEI to make digital images of letters written 100 years ago computer-readable and thus a valuable resource for those interested in or studying the events of that volatile time.
One of principal goals of The Letters of 1916 crowdsourcing project is to collect good quality transcriptions of the letters stored in our digital archive. These transcriptions will eventually form a digital scholarly edition and will be used as texts for historical and academic studies as well as general reading/consultation. In order to improve the search results and for advanced research, our text transcriptions are encoded in TEI-compliant XML.
The structure of a TEI schema is basically the same as the type of schema used in HTML: it has two main parts, the TEI-Header, tagged <teiHeader>, and the “textstructure”, tagged between the <text>/<body> tags. The <teiHeader> provides, in essence, a descriptive record that collects basic information about the document, its bibliographic history, and information about the digital object. The second section is the ‘core’ part of the document and includes content of the item, in our case the letter transcriptions.
TEI in The Letters 1916: metadata & TEI-Header
As those who have contributed letters to the project already know, when images are added to the Letters of 1916 site, it is necessary to input some basic data (such as the date of the letter, the sender and recipient etc.). This information is known as ‘metadata’. This metadata is contained in our ‘upload form’ becomes part of the <teiHeader> (see the Fig. 1).
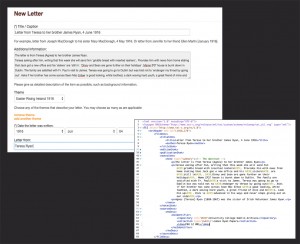
When creating a digital scholarly edition, it is important to capture the same kind of information as a more traditional publication might. The information must follow the Letters of 1916 style guide (see the guidelines: LINK). It is also important that all metadata is correct and accurate. The output of the ‘TEI-header’ can be likened to the cover and frontispiece of a book, where a reader might retrieve the credentials and bibliographic details of the volume.
TEI in The Letters 1916: tagging the transcriptions
In order to add TEI mark-up to the letter transcriptions, our site implements a toolbar that can be used to identify certain features of the letters. We refer to the portion of text wrapped inside a tag, as an ‘element’. There are different types of elements: some point out the semantic meaning of the text (the pink ones in the grid below, see Fig. 2); others simply describe the position or the formatting of the text, while the remaining tags provide information about uncertainty (eg. spelling or handwriting) or can be used to submit comments to the editors.
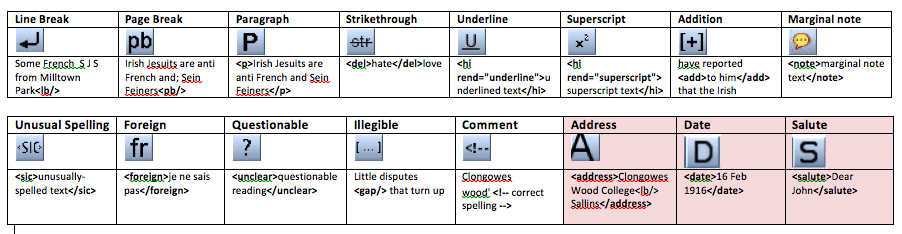
Essentially, we allow users to add all these kinds of mark-up. Semantic elements such as <date>, <address> or <salute> provide information such as the sender’s address, or the “My dearest Pierce,” salutation which is used to open the letter below: see Fig. 3.

Towards a Digital Scholarly Edition
So far the Letters of 1916 archive has collected over 2200 letters from more than 20 institutions and over 40 private contributors (LINK). To date, the project has over 1100 transcribers which have played a major part in the transcription process. Since the project’s launch in 2013, users have been transcribing letters in a transcription desk environment. In the next phase of the project, all of these letters be searchable and that requires migrating the digital items to the new site. A ‘digital scholarly edition’ requires rigorous checking of the accuracy of the all data input so far, both metadata and transcriptions. The process is twofold: firstly automated scripts clean and refine the structured TEI compliant template, and secondly a team of editors ensures the accuracy of the final data. It is important to remember that all of this data is the basis not only for the general search and browse feature, but also for more sophisticated and automatic analyses.
The Letters of 1916 @ TEI Conference 2015
This year, the annual TEI conference (http://tei2015.huma-num.fr/en/) took place in the French city of Lyon from 28 to 31 October. In the “Correspondence in TEI” session, members of The Letters of 1916 team presented a paper entitled ‘From Crowdsourced Collection to Digital Scholarly Edition: the Example of the Letters of 1916 Project’.
Richard Hadden and Linda Spinazzè, both DiXit researchers, gave a 20 minute presentation which they co-wrote with Roman Bleier Digital Arts and Humanities (DAH) researcher. The main focus of the paper was on the strategies used to align crowdsourcing methods with the accuracy of producing a Digital Scholarly Edition.
A brief analysis of the main issues and errors which we found in the transcriptions was followed by an explanation of the workflow which is currently used for proofing the transcriptions.
After the presentation a lively discussion ensued about overcoming problems when creating valid findable, reusable, shareable TEI metadata and text.
Click here to view the presentation in Slide Share

Blog post by Linda Spinazzè
Conference presentation: Roman Bleier, Richard Hadden and Linda Spinazzè.